
LLM data bottlenecks: where are we today?
Will foundation models hit a data bottleneck?

In this document I will investigate a few questions regarding the Scaling Hypothesis and forecasting about AGI, with a special focus on data bottlenecks. It is mainly written for myself but I will try to make things somewhat coherent and accessible.
Main questions:
i) What is the status of the data bottleneck problem today?
ii) Will synthetic data overcome data bottlenecks and give us “escape velocity” towards AGI?
iii) How are frontier labs employing synthetic data today?
iv) What about multimodal data? Do scaling laws like Chinchilla continue to apply when we incorporate multimodal data?
v) What about robots? Can we use robots to get “feedback” from physical environments in order to overcome data bottlenecks?
I. Data Bottlenecks
Modern-day LLMs are close to exhausting the entire Internet. To level-set here, let’s consider some numbers from an Epoch AI report from August 2024.
Human Brain Size: 8.6e10 neurons
Lifetime Human "Training Set": ~1e9 tokens
Rough estimate for a 100-year-old human
Source; very rough estimate, 2e8*5 for 20 year-old
2025 Frontier AI Models: 2e12 parameters
Based on Llama 4, released April 2025
Note: Counting Mixture of Experts (MoE) parameters naively
2025 Training Set Sizes: 1.5e13 tokens
Size of the Internet: 1e15-5e14 tokens
This page and this paper
Note that the sum total of all multimodal datasets and RL simulations does not meaningfully increase this number, as we will see later
Total Private + Public Data in Existence: 3e15 tokens
This page and this paper
See this page for more detailed breakdowns. One thing to notice is that modern day systems already use OOMs more parameters and more data than the human brain. This tells us these systems are doing something quite different than the brain, and that the inductive bias of the human brain due to our genetics is a significant aspect of our intelligence.
We know that more data, more compute, and more model parameters are the keys to scaling. These can all be mutually substituted to some extent, but not infinitely so. Therefore, we have a critical question: how will we generate orders of magnitude more high-quality data than the existing Internet.
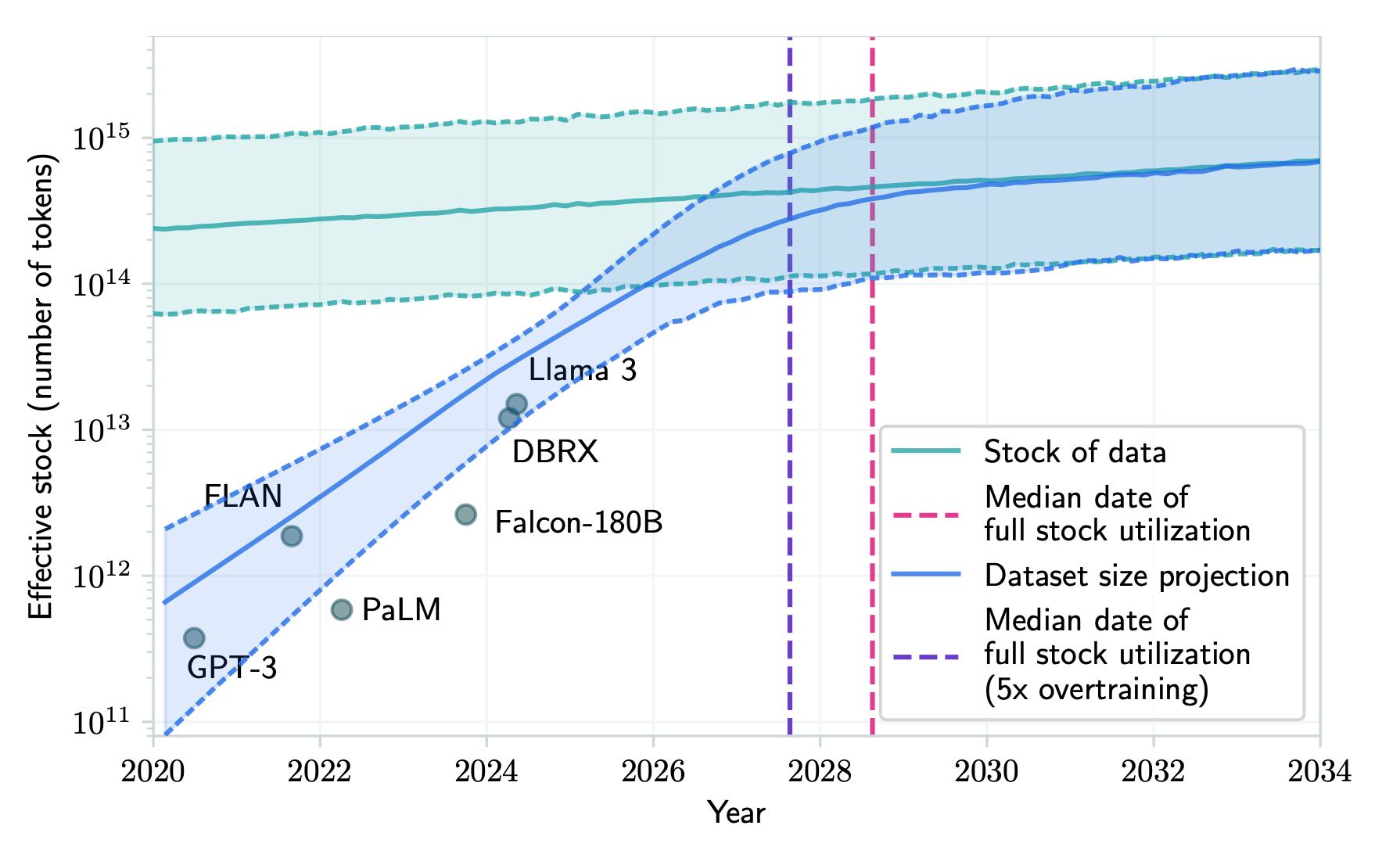
Figure: Current and projected data usage of frontier models, from an Epoch AI position paper.
Some plausible ideas for how to avoid this data bottleneck include multimodal data and real-world data from embodied systems interacting with physical environments — I will discuss these later in this post. However, simply relying on growth of public Internet data is likely insufficient. A major concern is the Ouroboros effect, where the production of AI-generated information on the internet pollutes existing datasets and causes model collapse. Furthermore, data quantity cannot make up for poor quality. What we really need are high-quality data on domains that are not highly present in existing datasets, such as textbooks and research papers. The vast majority of Internet data will not be helpful in this regard.
Finally, some might suggest paying humans at scale to generate data. I think this will fail for similar reasons as above. Essentially, we are taking a tiny fraction of the already enormous quantities of data that humans are generating for us for free, and then automating it.
As a very rough heuristic, let’s think about what fraction of the global workforce could be induced to give up their existing jobs in order to generate data full-time. Clearly the more skilled and in-demand workers will demand a higher salary to do this. Companies can do whatever allocation split they like here, but ultimately they’ll create internal companies of sorts, whose job is just to create data of some kind. Suppose the market cap of this internal company is comparable to a large multinational like Nike (so, under 1 trillion USD). Even working with complete focus and coordination, this just doesn’t end up being a lot of data when compared to the entire Internet. Humans can augment the data generation process, but to really get OOM scaling, we need some kind of automation.
Rather than paying humans to generate data, I would speculate that high-quality data will likely come from the sorts of things that motivate humans today: prestige, high pay, an ability to challenge oneself in their creative work, etc. Institutions today already struggle with this, and I think an Amazon Turk style setup where individual humans sit in front of a computer all day and click or type mindlessly would be much worse in this regard.
Note that with enough effort this last objection could be overcome. However, scale is the name of the game here. What I am arguing is that if OpenAI or Anthropic were given $10 billion tomorrow to use on human-generated data projects, it would be fairly hard to spend all that money in an efficient way. If instead they had trillions to spend then they probably could solve more of these problems, but that would be a substantially different world.
The final idea, which I think is the crux of current bottleneck discussions, is self-play with synthetic data. This is the subject of the next section.
II. Will synthetic data give us the escape velocity needed to get to AGI?
In short: I don’t think so. My main claim is that you cannot build a perpetual motion machine.
This is a well-established fact in physics, and one that applies equally to information theory in the form of the data processing inequality.
To use an analogy:
Second Law of Thermodynamics <—-> Data Processing Inequality
In more detail:
In a closed system, entropy can never decrease <—-> Data processing steps can never increase information

Figure: The basic data processing inequality, from Wikipedia.
The nomenclature here is not my own. Jennifer Listgarten (who is a Computer Science professor at Berkeley, and a well established computer scientist who has been working on life sciences + AI for the past decade and has very strong “pure” CS credentials) has written a convincing article to this effect, with a special focus on the biological sciences since they are especially data-constrained.
So this is the theoretical claim, which is mathematically sound. One could argue that theory and empirics are very divorced when it comes to deep learning. After the Bitter Lesson of RL, maybe we should just let empirics guide our forecasting and ignore math. I’m not unsympathetic to this view, and I want to explore some of the purely empirical work on synthetic data out there, even if I do personally continue to believe in information theory. Still, I don’t think it is earth-shattering, as we will see next.
Self-play in game environments
AlphaZero was a very nice demonstration of the synthetic data self-play paradigm. What it showed was: for the right architecture, in a narrowly constrained game environment, synthetic data generated purely from self-play is enough to train a superhuman system. DeepMind did it for Go, Chess, and – impressively – for StarCraft. This is a huge achievement!
Key question: What are the domains in which there is enough feedback to do AlphaZero-style self play and achieve superhuman results?
If the answer is all domains, then compute is enough to achieve AGI. But I don’t think we live in that world. We should, however, do the following experiment.
Key experiment: Given each domain X, how effective is the best model when trained purely through self-play? How does performance scale with compute in this data-free setup?
We’ve done this for X = Go, X = Chess etc but not for more open-ended domains. It looks X = “mathematical theorem proving” is proving to be fruitful in 2025 as well, but these are still relatively narrow domains.
Clearly some domains offer more immediate feedback, such as video games. Embodied environments of certain kinds might also offer feedback in the form of intermediate-level goals like “nobody is dead” or “the traffic light was green the entire time my car was in the intersection.” As we throw more compute and resources into domains like math, programming, self-driving cars, and humanoid robots, I do think this will be fruitful; but long-term reasoning and planning tasks will prove difficult.
Chain of Thought and Tree Search methods
In addition to self-play, there’s Chain of Thought prompting and inference-time compute. Unlike AlphaZero, this is a feedback-free method, which is great because it may generalize to more domains. The model can just revise its own reasoning by talking to itself. Note that these are largely akin to tree search methods, which featured prominently in AlphaZero as well.
Figure: A common issue in the presentation of model performance results in AI papers. This is from a Reddit thread on the GPT o1 announcement.
Unfortunately, it seems like CoT performance scales only logarithmically with compute at test time – that is, we require exponentially more compute to get a linear performance gain (not surprising for a tree search type method). If true, then it’s game over for CoT as a path to ASI. We cannot defeat the exponential function. We can cover the Sahara in solar panels and GPUs and the exponential function will just laugh in our faces. So this is a crucial question.
Key question: how does the performance of CoT reasoning and test-time compute scale with the amount of compute used?
Also, here I come back to the data processing inequality. What CoT prompting reveals is that the modern day LLMs are not leveraging their internal representations as well as they could be when answering questions in a one-shot fashion. But at the end of the day, without fresh information, they cannot infinitely improve their reasoning through mere reflection.
What about that chart from METR (see below) that shows the effective task time for AI agents is doubling every 7 months?
I think this is very interesting and I’d like understand how hard we can push the compute-efficiency here. My intuition is that RL post-training of LLMs is a way of surfacing implicit information more efficiently than prompting can. This is because LLMs are not trained in an information-theoretically optimal way, and prompts are not optimal among the space of short token sequences that result in a particular answer. However, at some point we reach optimality and the curve saturates. If and where the curve saturates, if at all, is not clear. In general, I would say that any S-curves can look like exponential curves at first, and we don’t have a great way of knowing which regime we are in today.

Figure: A recent METR report finds that the length of tasks that AI agents can complete with 50+% reliability is doubling every 7 months. The “task length” is how long a human professional would take.
LLMs with self-play
There is some evidence that self-play can increase LLM performance without fresh data. For example, a paper with 500+ citations from ICML 2024 describes SPIN, which is an algorithm for LLM fine-tuning that essentially combines fine-tuning with GANs. The algorithm is roughly:
Get a pretrained LLM and a labeled fine-tuning dataset D
The current iteration of the model generates responses to prompts within D
Train a new model which can distinguish between the responses generated in step 2 from the true labels in D.
Update the current model to be the model trained in Step 3.
This paper shows some nice performance improvements over ordinary RLHF techniques. However, it is not employing bona fide synthetic data! The dataset D is already labeled, and the “signal” at each iteration of step 3 is precisely the true labels from D, which the new model must distinguish from the labels generated synthetically. At the end of the data, this iterative process will converge once all the signal has been squeezed out of D.
In a different setting, there is a paper from NeurIPS 2024 that shows how using both positive and negative synthetic data together can increase performance of LLMs for mathematical reasoning tasks specifically. This is not surprising, because math is a kind of game where proof correctness/incorrectness is a source of continual fresh data that helps avoid the data processing inequality.
Model collapse is bad news
Finally, a line of work on “model collapse” gives convincing evidence that synthetic data actually degrades model performance, for reasons similar to the well-observed mode collapse phenomenon in GANs. There is a very nice, short argument from Section 4.1 of the classic paper by Shumailov et al (later published in Nature).
Claim: Retraining on entirely synthetically generated data from a generative model of a finitely supported distribution causes the model to collapse to a Dirac delta function. That is, it eventually puts all the probability on a single point.
Proof: Consider a sequence of models M0, M1, … where M0 is trained on the original dataset X0, M1 is trained on a dataset X1 generated by M0, and so on. We can show that the sequence of datasets X0, X1, … form a Markov chain. Now, suppose at some step k, the dataset Xk consists entirely of a single point repeated over and over again. That is, Xk = {x, x, …, x} for some point x. Then X(k+1) will also be exactly {x, x, …, x}, and same for X(k+2), and so on. Therefore the Dirac delta function at {x} is a stationary point of the Markov chain. We can show that all stationary points are Dirac delta functions. By standard ergodic theory, the sequence of data X0, X1, … will always converge to a Dirac delta.
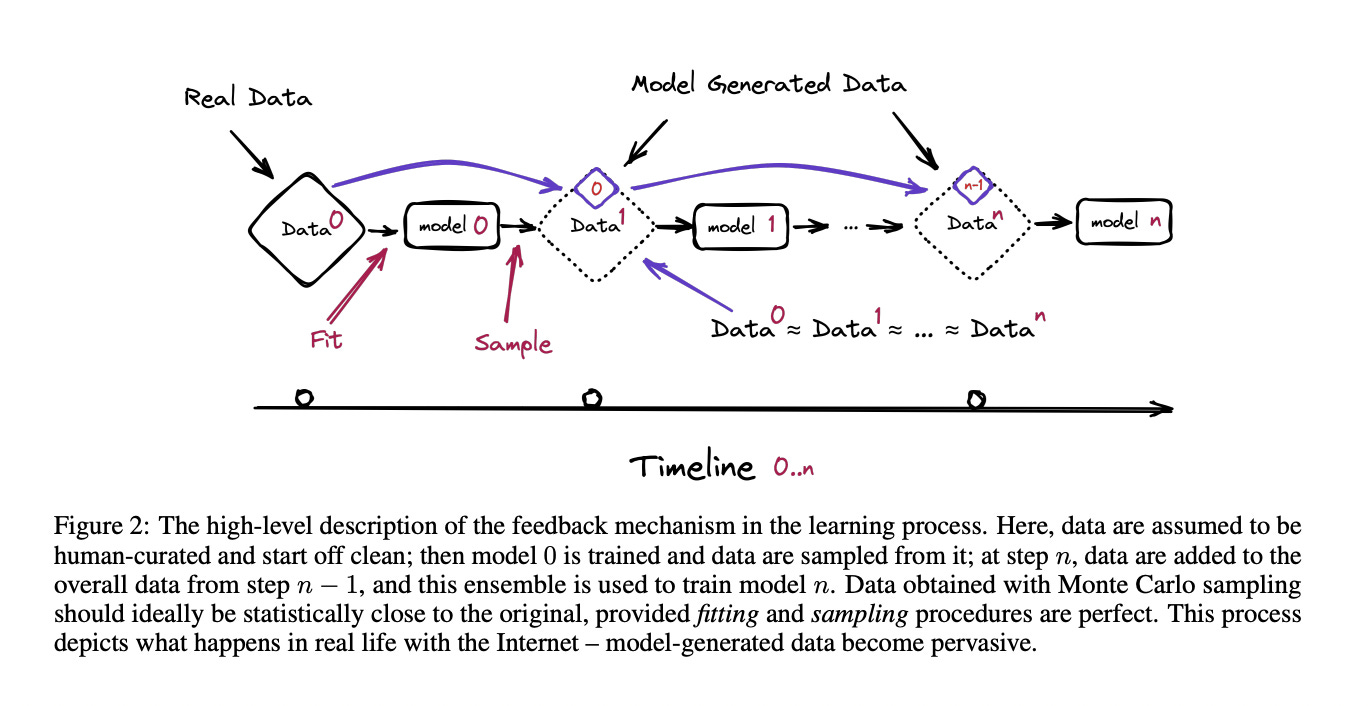
Figure: Description of model collapse, from Shumailov et al.
III. How are frontier labs employing synthetic data today?
So far I’ve mainly referenced academic papers and open-source models like Llama, because that’s what we actually know about. What about the private AI labs like OpenAI, Anthropic, and Google? There are many industry insiders and industry-adjacency people with very short AGI timelines. They seem to largely believe that synthetic data will work. Let’s dig into these claims a bit.

Figure: Some speculation from AI 2027.

Figure: L. Aschenbrenner says, in the infamous ‘Situational Awareness’ essay, that the frontier AI labs “will probably figure out some crazy stuff – essentially, the ‘AlphaGo self-play’ equivalent for general intelligence.’” It’s hard to evaluate these claims as an outsider.
Let’s begin with a claim made in the “Situational Awareness” essay from 2024.
All of the labs are rumored to be making massive research bets on new algorithmic improvements or approaches to get around this. Researchers are purportedly trying many strategies, from synthetic data to self-play and RL approaches. Industry insiders seem to be very bullish: Dario Amodei (CEO of Anthropic) recently said on a podcast: “if you look at it very naively we’re not that far from running out of data [...] My guess is that this will not be a blocker [. . . ] There’s just many different ways to do it.” Of course, any research results on this are proprietary and not being published these days.
Both links are to Dwarkesh Patel’s work (a fellow UT Austin alumnus, incidentally – hook ‘em).
Will Scaling Work? https://www.dwarkesh.com/p/will-scaling-work
Dario Amodei Interview: https://www.dwarkesh.com/p/dario-amodei
In the “Will Scaling Work” essay, Dwarkesh discusses various perspectives on scaling in a sort of review article fashion. On the “believer” side, he employs an intuition pump which I don’t think is that convincing.
If your main objection to scale working is just the lack of data, your intuitive reaction should not be, “Well it looks we could have produced AGI by scaling up a transformer++, but I guess we’re gonna run out of data first.” Your reaction should be, “Holy fuck [sic], if the internet was a lot bigger, scaling up a model whose basic structure I could write in a few hundred lines of Python code would have produced a human level mind. It's a crazy fact about the world that it’s this easy to make big-blobs-of-compute intelligent.
I’m very happy to say “holy fuck!” in response to recent LLM progress. These advances are a big deal. We just cracked the Turing test, which is impressive enough itself! But, that doesn’t mean synthetic data will be enough. I don’t think it’s surprising that the current AI paradigm, which involves datasets orders of magnitude larger than what the human brain requires to learn, will in fact run into data bottlenecks. There are also other reasons to doubt the broader scaling hypothesis, some of which I’ve discussed, so it’s a bit of a strawman to say that this is the only objection one might have within this general topic.
Next, Dwarkesh argues that models just need to be better at judging their own reasoning than de novo.
Self play doesn’t require models to be perfect at judging their own reasoning. They just have to be better at evaluating reasoning than at doing it de novo (which clearly already seems to be the case - see Constitutional AI, or just play around GPT for a few minutes, and notice that it seems better at explaining why what you wrote down is wrong than it is at coming up with the right answer by itself)4.
Here we see a concrete example in the form of Constitutional AI. This was a paper published in late 2022 by Anthropic which used a “Constitution” as the only human-generated data in the fine-tuning process for Claude. This is a nice idea, but it is more useful for alignment and safety than for superhuman performance on hard reasoning tasks. What would the Constitution for the biochemistry expert LLM be? “You are a scientist. Be smart, do good science, don’t hurt anyone”? This may be directionally useful but I don’t believe it’s a paradigm shift in LLM inference.
Indeed, the Constitutional approach seems analogous to system prompt design, which is important but generally doesn’t lead to OOM improvements in performance. On the Constitutional AI website, I don’t see any technical blogs or announcements past 2023, although of course Anthropic has been quite busy as a company. Still, it doesn’t seem like Constitutional AI has really broken through yet. I guess it remains to be seen.
Later on Dwarkesh links to the Q* announcement from OpenAI, but this just seems to be an earlier version of CoT prompting – nothing new in 2025.
Figure: An example Constitutional approach for Claude. Source.
Finally Dwarkesh uses an appeal to authority, and again a reference to his Dario Amodei podcast. I don’t doubt that Dario is a smart person, but there is simply no argument being offered here. “I have a solution to the data bottleneck problem but it’s a secret” is a great pitch to VCs, but not a convincing argument to the broader public. When all of the publicly available academic and open source research does not indicate a huge breakthrough in synthetic data generation, I don’t think the loud protests of AI frontier labs should hold much weight.
Almost all the researchers I talk to in the big AI labs are quite confident they’ll get self-play to work. And when I ask why they’re so sure, they heave for a moment, as if they’re bursting to explain all their ideas. But then they remember that confidentiality is a thing, and say, “I can’t tell you specifics, but there’s so much low hanging fruit in terms of what we can try here.” Or as Dario Amodei (CEO of Anthropic) told me on my podcast:
Dwarkesh Patel (00:10:01 - 00:10:06): You mentioned that data is likely not to be the constraint. Why do you think that is the case?
Dario Amodei (00:10:06 - 00:10:22): There's various possibilities here and for a number of reasons I shouldn't go into the details, but there's many sources of data in the world and there's many ways that you can also generate data. My guess is that this will not be a blocker. Maybe it would be better if it was, but it won't be.
Claims about insider information are likely a crux for anyone reading this essay. If you believe that frontier labs are truly effective at hiding breakthroughs (I don’t), then it’s quite plausible that we’ve already achieved some. It’s hard to test these hypotheses without access to such information, but if we start seeing substantially higher GDP growth per year (say, 10%) due to AI advancements, as Satya Nadella suggested on Dwarkesh’s podcast, I think that would decisively refute my position here.
IV. Scaling laws for multimodal data?
Unimodal Scaling
Let’s recall the ordinary Chinchilla scaling laws, which tell us how much the loss of an LLM decays when trained on only text data (for one epoch, with a cosine learning rate schedule).
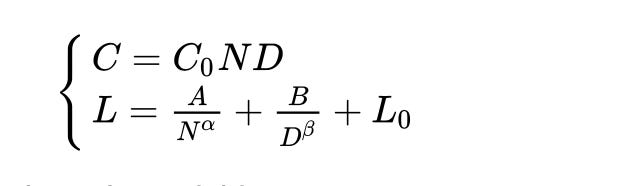
Figure: Chinchilla scaling laws describe how the loss L scales as a function of dataset size, model size, and other parameters.
Here:
L is model loss
N is number of parameters of the model
D is number of dataset tokens
L_0 is the theoretically best loss
The key parameters are alpha and beta, which are roughly 0.25-0.4 (Ajeya Cotra has given some smaller estimates like beta=0.1, which you can see here, but I don’t know the details of this estimate and note that it is from 2020). It is known that neither alpha nor beta can be more than 0.5 (source). Roughly speaking what this says is that to get a 10x improvement in LLM loss (before saturation), you need to 1000x your dataset size, all else constant.
Therefore, going from a dataset of 1e13 tokens to 1e15 tokens should improve loss by a factor of 5.
Multimodal scaling and synergies
A 5x improvement in model performance will probably not get us to AGI, so we need fresh data. Here is where multi-modality comes in. We will hope to train models on a combination of text, images, videos, etc and hope that they learn shared representations between modalities so as to have a more holistic intelligence.
First of all, how much additional data do we get by incorporating images and text? Not so much, it turns out. From this paper, the total stock of image data is equivalent to 3e14 tokens, while videos are 1.35e15 tokens. This is 100x the dataset sizes used to train LLMs today. See figures below as well.
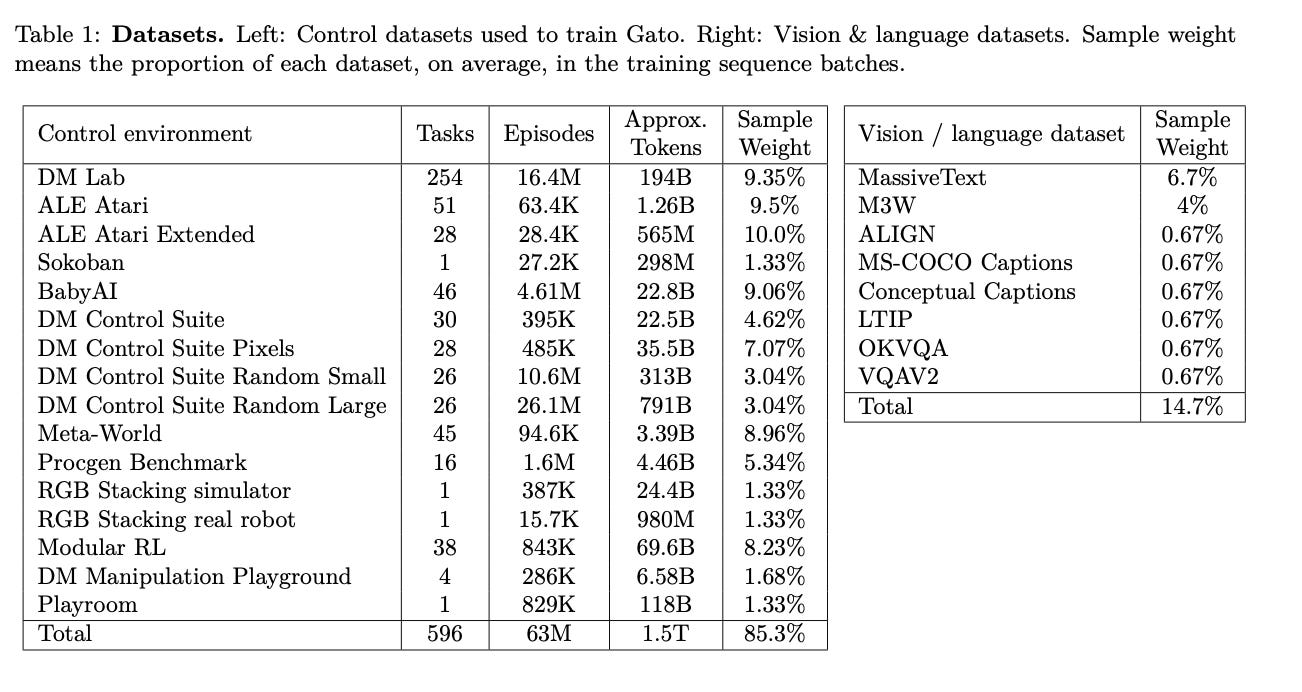
Figure: Datasets for DeepMind’s 2022 Gato paper, which trains a generalist agent on multimodal data including RL environments, images, and text. Note that total RL dataset size is roughly 1.5 trillion tokens, which is about 10% of the dataset size for a 2025 foundation model.

Figure: Dataset size estimates for Epoch AI's 2024 paper. Note that modern foundation models train on about 15 trillion tokens.
Second, what about synergies? Can the whole be greater than the sum of its parts when it comes to multimodal training? A recent paper from ICML 2023 develops scaling laws for multimodal data and investigates the extent to which we can beat the Chinchilla scaling laws with multimodality. It comes down to a synergy parameter, marked in blue below.

Figure: Scaling laws when we have two different data modalities D_i and D_j. We get a modified version of the Chinchilla scaling laws (marked in purple) which depend on the synergy of the datasets (marked in blue), but we also do worse due to competition in functional approximation (green) and competition in optimization (orange). If the number C_{i,j} (the synergy factor) is very large, then multimodal models are “greater than the sum of their parts.” Source.
It turns out that there is synergy once datasets grow large enough: this is called the competition barrier. Experimentally, the authors find that this synergy does start to kick in for certain dataset pairings, like speech + text. But the gains are quite modest – see the figure below.
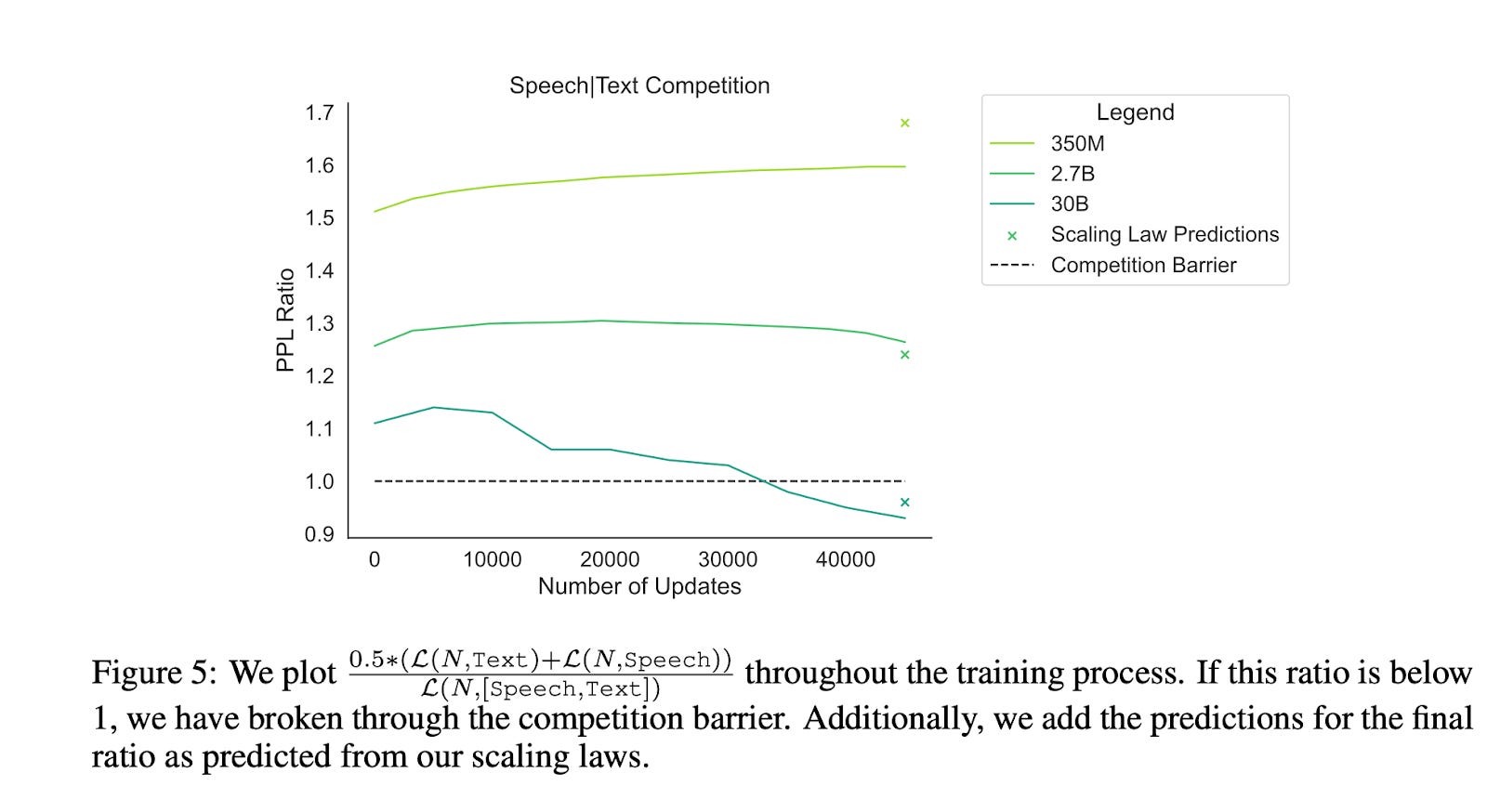
Figure: For a large enough model (dark blue line) we see some energy, but there is barely any gain.
Finally, what do the best (industry) multimodal models of today look like?
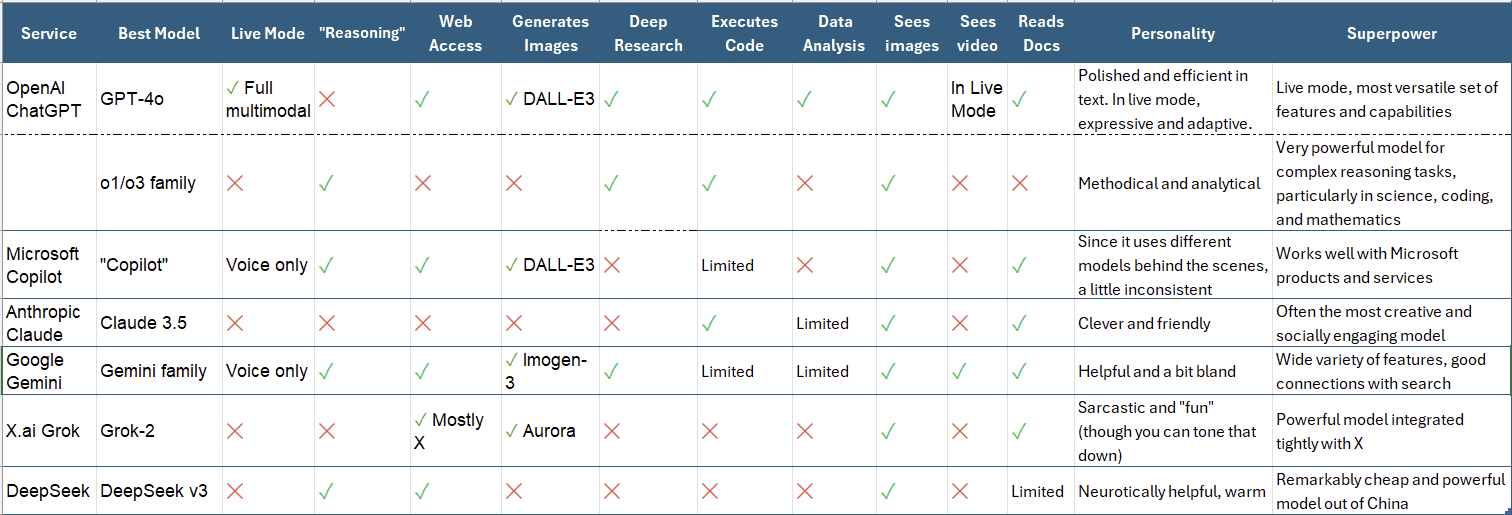
Table: An overview of models in January 2025. Source.
It turns out that a lot of the leading models are inherently multimodal already. If there were some huge capabilities leap in going from text to multimodal, we would have probably crossed it by now. That’s not to say multimodality is not useful; rather, as an intelligent commentator put it to me recently, “Native multimodality is essentially table stakes for leading AI labs today.”
The dream of multimodality is that learning a shared representation of concepts like “dog” from text, images, videos, and other formats might encourage a new form of representation learning which is substantially better than text-only representations of “dog”. Clearly multimodality is somewhat better, but as far as I know it hasn’t had a huge effect.
I should note that this story also appears to be happening in other kinds of multimodal representation learning, such as protein language models – see this recent paper. The idea here was to combine amino-acid sequence data with 3D protein structure data; they did see improvements, but the story has some nuance as well. I think this line of work is fairly young and it remains to be seen how much synergies exist between biological and chemical data modalities.
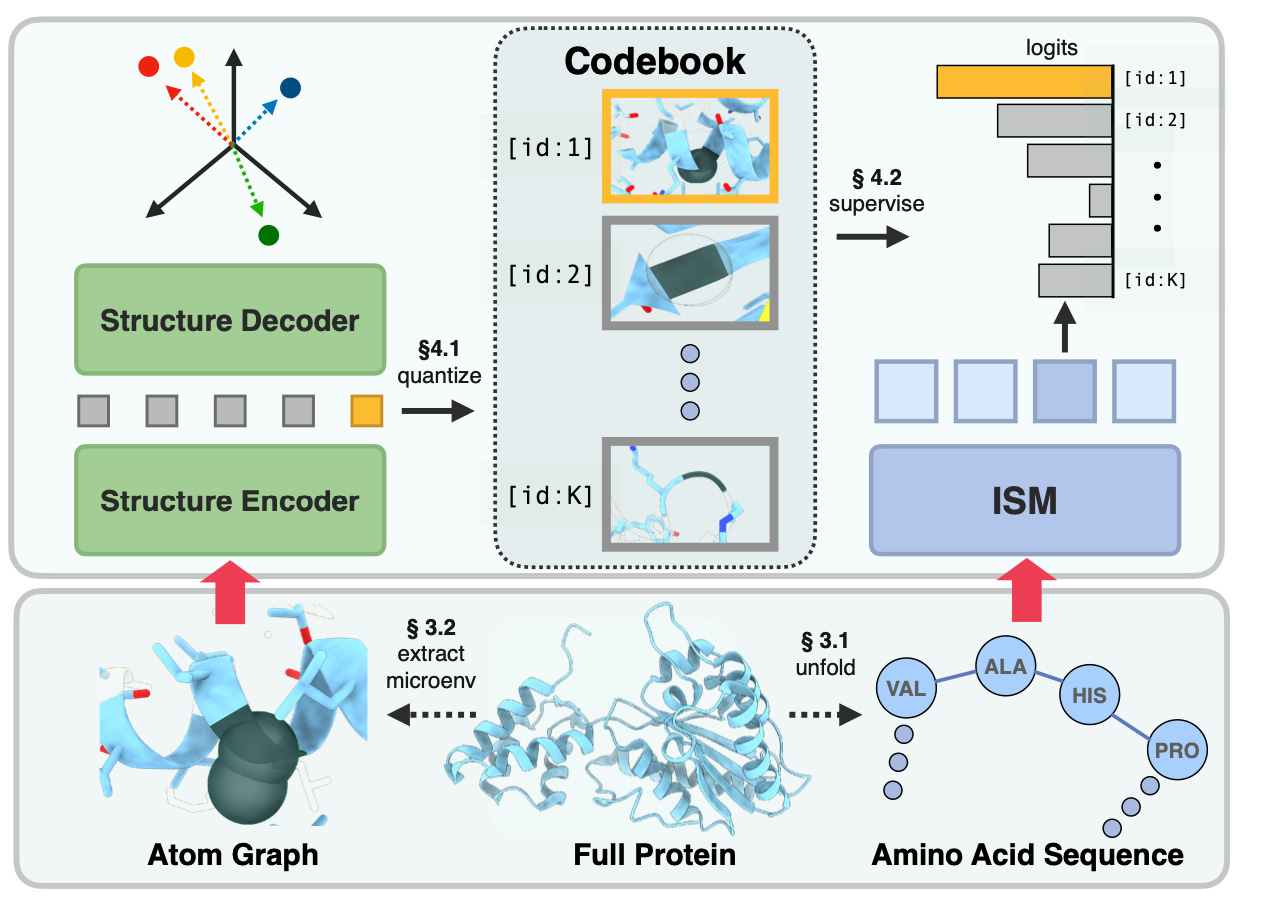
Figure: A recent paper (ICLR 2025) combines protein structural information from the atom graph and sequence information from the amino acid sequence to enable better protein sequence models.
V. What about robots that get fresh data by interacting with the world?
A promising approach to avoiding data bottlenecks is to use the physical world as a source of fresh entropy (information). So far we’ve discussed two kinds of data, which lie at two extremes:
Perfect feedback (supervised): Games like Go and Chess, where one has “infinite data” through the reward structure of the game that is perfectly known.
Zero feedback (self-supervised): Datasets like language, images, and speech audio, where one has no feedback other than the arbitrarily constructed “autocomplete” reward function of self-supervised learning.
Real-world environments might lie in the middle. First of all, real-world environments offer many “mini games” that can emulate the perfect feedback setting within a broader task framework. For example a self-driving car might have an intermediate goal of “don’t hit pedestrians” or “only cross at green lights.” In this case the environment offers a lot of entropy in the form of different weather conditions, road types, etc. but also has intermediate signals of reward that can be used for RL.
Second, real-world environments offer more opportunities to refine and combine previous representations such as a driving algorithm from simulated environments. If we were training purely in the OpenAI Gym, there would be a limit to the amount of entropy that our simulated driver could experience; but the real-world involves a distribution shift which will force the model to update its representations but in a hopefully data-efficient fashion.
So – what is the state of the art for robotic systems that get fresh data from interaction with the real world? I’ll review that in this section, but first let me take a theoretical digression to talk about information-computation gaps.
What are information-computation gaps and why do they matter?
Earlier I discussed the data processing inequality, which says that algorithmic processing can never increase information. A sort of converse to this result is Shannon’s coding theorem, which says that communication across a noisy channel that approaches the information-theoretic limit is possible. In other words, optimal compression algorithms exist for noisy channels.
How do we find these optimal compressions? As it turns out, doing so will be computationally infeasible in general. The perfect encodings exist, but require exponentially large computing resources to actually find. More generally, information-computation gaps (see e.g. this overview) say that statistically optimal things are computationally infeasible to find.
Neural networks are computationally feasible; therefore, they are very likely not statistically optimal. There are better compression algorithms (or generative models, if you prefer) out there somewhere. But we will, for practical purposes, never find out what these are! It’s not fair to hold neural networks to this high standard of optimal compression. Instead we should ask: among all computationally efficient compression algorithms, how good are neural networks?
Quite good, as it turns out. One way of interpreting the massive success of transformer architectures is that everything else we were doing was much, much worse. Transformers almost surely cannot be optimal, because they are computationally possible to find. But still, the other machine learning methods of the time were so much worse that transformers still won out.
So why does this matter? Because we might hope that when combining neural network based generative models with a little bit of real-world feedback, we can end up doing much better neural networks without that data. In other words, because transformers are so far from being optimal, we might hope that by introducing a little bit of entropy into their training process, we can end up doing much better than otherwise.
Schematically, we might say that:
Information theoretically optimal algorithms are
much better than
Transformers with a bit of fresh entropy from the real world, which are
much better than
Transformers trained purely on simulated or artificial environments, which are
much better than
Classical machine learning algorithms like kernel methods.
Some RL papers
Let’s consider a NeurIPS 2023 paper on Synthetic Experience Replay, which involves upsampling RL rollout data with a diffusion model to get more data-efficient training. The story here is what I outlined above – they leverage the pre-trained representations from the diffusion model to generate higher-quality datasets at functionally zero additional cost, since real-world data is at a premium and dominates the cost of the training loop. The reason they avoid the data processing inequality is that the diffusion model contains a lot of additional entropy that is missing in the real-world data, so even though it cannot perfectly up-sample all real-world environments, it is quite good for the “bulk distribution” inputs like dashcam video from a shady suburban road. Empirically, they see improved performance on the Walker2D environment.
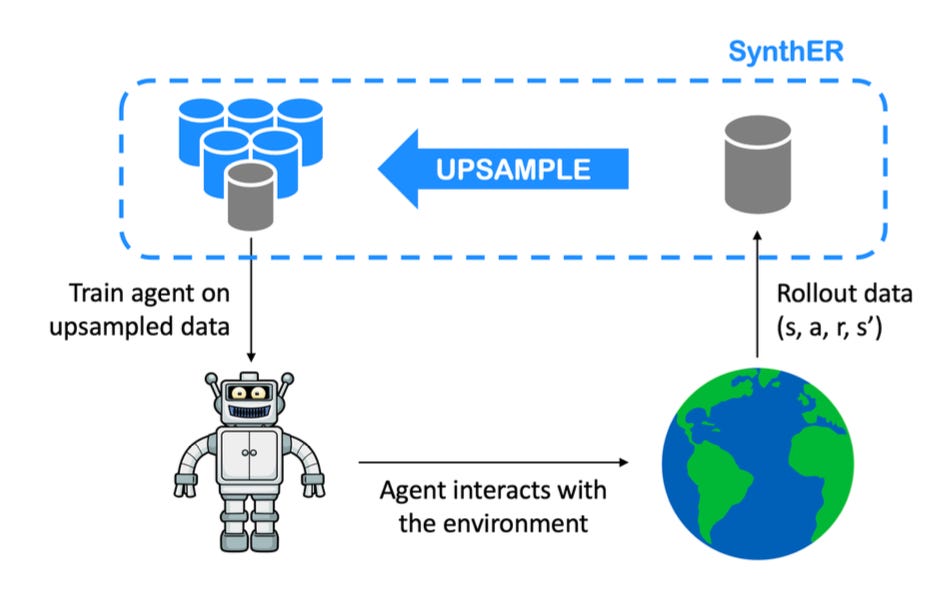
Figure: The Synthetic Experience Replay paper involves taking a collection of RL rollout data, upsampling it with a diffusion model, and then training the agent on the upsampled data. The claim is that this additional upsampling step, outlined in blue, results in much more data-efficient training.
Indeed, the authors themselves argue that the strength of their method lies in the generalization capacity of the diffusion models they use (see Figure below). Because the diffusion model generalizes the dynamics better than noise, the upsampled data spans a broader swathe of the overall rollout space while still faithfully capturing the ground truth dynamics.
It should be noted that this will fail at the limit – if we were to iteratively upsample over and over again with a diffusion model (or any non-perfect generative model) we would start to see a model collapse, as seen in previous sections. The point of the SynthER paper is that a careful choice of “temperature” in the up-sampling step can achieve significant gains, assuming a good diffusion model. The worse the diffusion model, the more limited the value of this step.
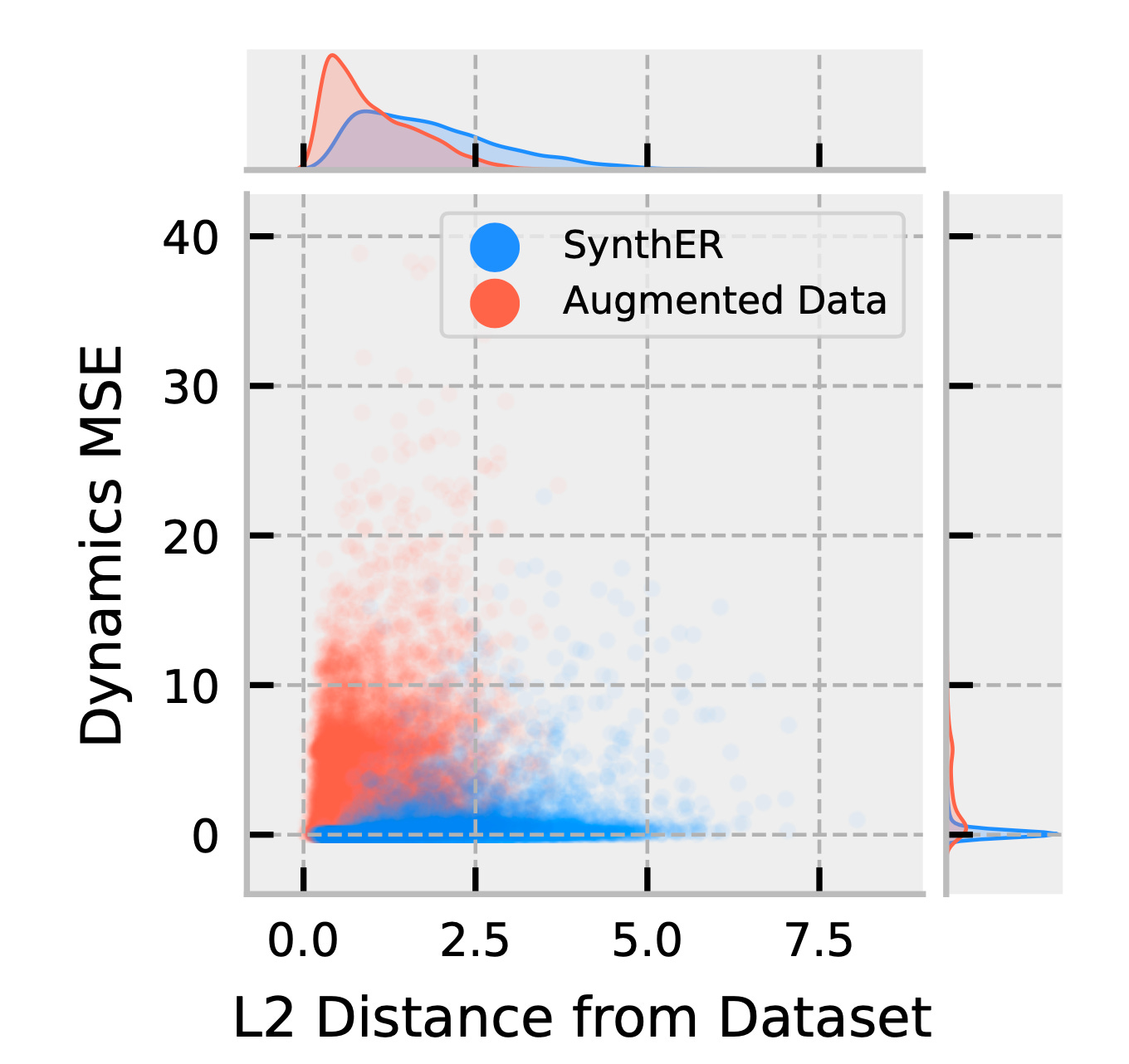
Figure: The Synthetic Experience Replay paper uses a diffusion model to upsample rollout data in RL. The resulting data, shown in blue, is significantly better than just adding noise (red). Specifically, it is better at capturing the dynamics (y-axis) of the ground truth data, while also sampling a broader swathe of the overall space (x-axis). Therefore, the diffusion model captures the dynamics with a non-trivial signal-to-noise ratio (SNR).
What does this mean for the broader project of using real-world interaction as a source of fresh entropy? I’m not really sure. It does seem like generative models are having their moment in RL research, with many papers proposing up-sampling schemes similar to the SynthER idea (see Figure below). But the more interesting part of the loop – namely, using real-world interactions and generating reward signals from those – seems less well-studied, at least in academic work.
Figure: A NeurIPS 2024 paper proposes upsampling of RL input data using stable diffusion models. This overall strategy seems common, but the twist here was to use text-to-image representations rather than image-to-image. Overall, the upsampling rate is limited by the quality of representations learned in the diffusion model itself. No perpetual motion machines here, it seems.
What about private robotics companies?
I trust that the revolving door of academia and industry means that the academic literature is not too far behind the state-of-the-art in industry, if at all. The gap may be larger here because robots and physical hardware costs a lot of money, so academic labs will be less able to do the kinds of large-scale experiments that private companies are doing. Still, patent filings and press releases can give us some hints.
Tesla recently filed a synthetic data patent that seems to involve 2 ideas (see Figure below).
Modifying authentic sensor data by changing road conditions, lighting, etc. This seems in line with standard data augmentation techniques like rotating an image by keeping the label the same, or the SynthER technique of using diffusion and generative models to get more data from a real-world rollouts dataset.
Creating purely artificial environments akin to the OpenAI gym.
Neither of these seems particularly original or revolutionary; of course, they may be keeping their best trade secrets to themselves, but based on the patent filing itself I’m not impressed.
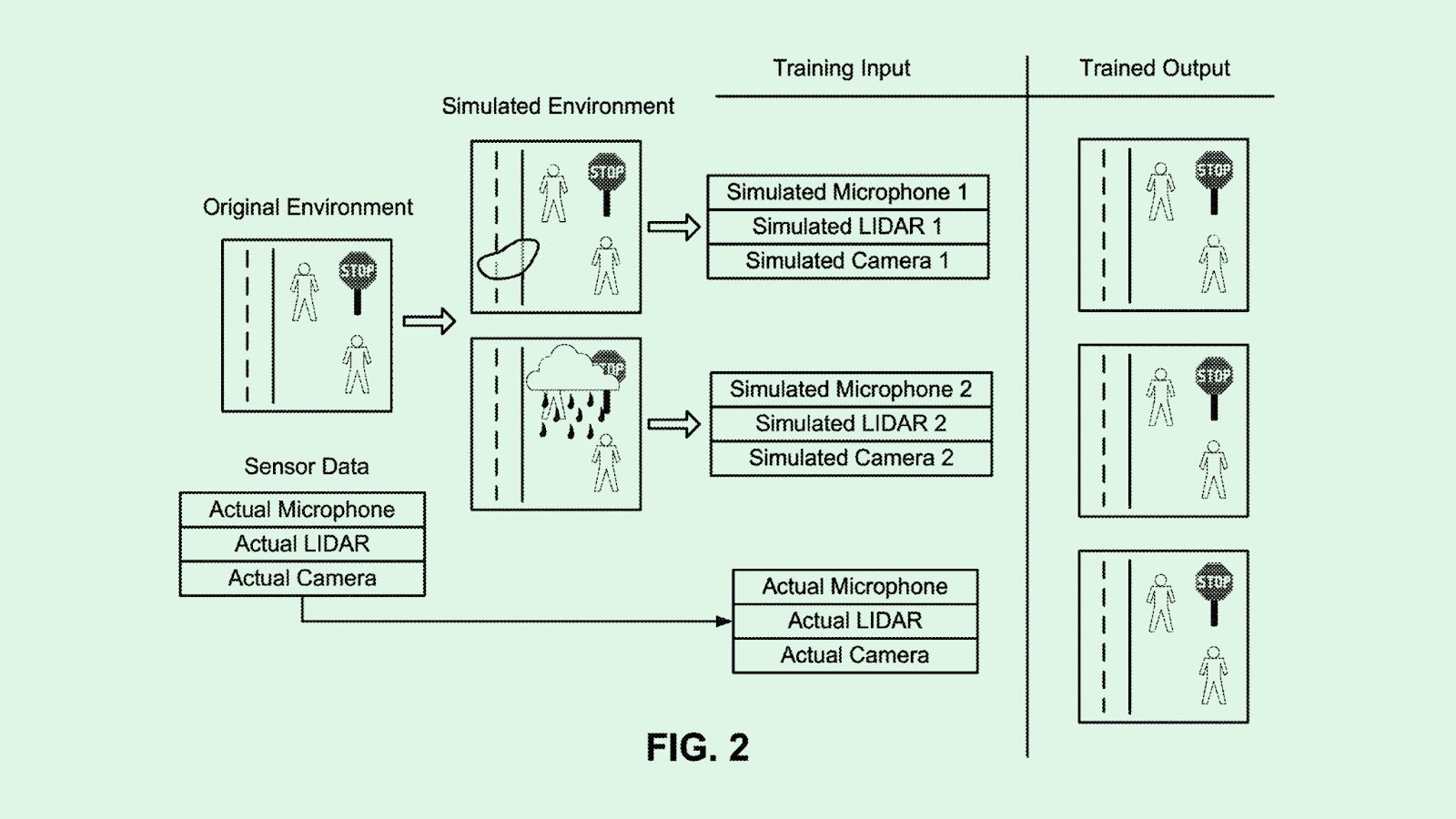
Figure: Illustration of Tesla’s synthetic data patent filing. Source.
Waymo also recently announced a self-driving foundation model, with some hints about synthetic data generation which sound fairly similar to Tesla’s approach. Quoting from a recent Fortune article,
The sensors gather data from various scenarios, collected during every trip a Waymo takes. The company also uses synthetic data to train Waymo with simulations of a broader diversity of situations—such as weather conditions—than it might encounter on the roads of Phoenix or San Francisco.
Waymo has developed a large-scale AI model called the Waymo Foundation Model that supports the vehicle’s ability to perceive its surroundings, predicts the behavior of others on the road, simulates scenarios and makes driving decisions. This massive model functions similarly to large language models (LLMs) like ChatGPT, which are trained on vast datasets to learn patterns and make predictions. Just as companies like OpenAI and Google have built newer multimodal models to combine different types of data (such as text as well as images, audio or video), Waymo’s AI integrates sensor data from multiple sources to understand its environment.
Multimodality, foundation model approach, synthetic data to modify weather conditions – check, check, and check. These are not new ideas within AI research.
Conclusion
Data bottlenecks are either already here or they are coming soon. I don’t think AI progress will necessarily slow down, but we will need to get more clever and work harder to continue to scale foundation models effectively. My view is that information theoretic ideas do matter – the data processing inequality will rear its ugly head, and researchers will need to carefully combine and filter datasets to ensure adequate synergies between modalities, avoid model collapse, scale parameter sizes in a compute-optimal fashion, and so on.
The key question is how good synthetic data can get. As I’ve argued, information-computation gaps indicate that real-world models are still quite far from the fundamental limitations of the data processing inequality. We can likely squeeze a lot more information out of the models we have. Moreover, domains like math and programming offer a lot of promise, since we can theoretically scale formal verification systems to massive levels and therefore generate unlimited synthetic data therein. Still, in the hardest domains – those with very limited datasets today, long horizons, and very ill-defined reward structures – I think we are very far from a “perpetual motion machine” that will take us all the way to AGI.
Let me conclude with a positive vision. I think that even if we paused all AI research today, the societal impact would take decades to fully play out. We are dealing with generationally important technology, and are still at a very early stage in its deployment. If we get it right, the systems of today can already reshape science, engineering, and knowledge work in amazing and positive ways – not to mention the new and improved systems coming down the pipeline in the next few years. I think the correct way to approach this societal integration step is precisely the same as how we should overcome bottlenecks in “pure” AI research – by opening up the field to more ideas and objectives.
If we look just at the intersection of biological modeling and AI, which is a huge area and relatively underserved in my opinion, this unique combination alone could keep the entire AI field busy for decades. There is not just biology+AI but also chemistry+AI (AlphaFold), law+AI (automating legal text search), mechanical engineering+AI (better AutoCAD), and so on. Each of these fields does not just improve itself with AI methods, but feeds back into the broader field of AI research itself. We come to understand more edge cases, different kinds of tail events, and discover new data modalities through deep engagement with specific domains. Ultimately, we are all scientists. I don’t know if we’ll get to AGI, but we can certainly do a great service to humanity along the way, and this is more than worthy of our life’s work.
Further Reading
(These are not organized at all, just sharing some helpful links and further reading).
Paper from Epoch and others on whether we will run out of data: https://arxiv.org/pdf/2211.04325v2
Dataset sizes, broken down by subtypes like books, patents, code: https://www.educatingsilicon.com/2024/05/09/how-much-llm-training-data-is-there-in-the-limit/#human-20
Jennifer Listgarten’s “perpetual motion machine” paper: https://www.nature.com/articles/s41587-023-02103-0
Chinchilla paper:
https://arxiv.org/abs/2203.15556
Ajeya Cotra biological anchors report and debate: https://forum.effectivealtruism.org/posts/NnygBgntvoGSuvsRH/ai-timelines-by-bio-anchors-the-debate-in-one-place
Paper on multimodal scaling laws from ICML 2023: https://arxiv.org/pdf/2301.03728
Anthropic Constitutional AI paper: https://ai-plans.com/file_storage/4f32fa39-3a01-46c7-878e-c92b7aa7165f_2212.08073v1.pdf
interesting read.
for the part on retraining models on entirely synthetic data collapsing into a dridac delta function, don't model params get initialized with some randomness at the start of each training run? So even if the previous run produces a uniform dataset, what gaurantees that the next run will if there is some noise added in between each traing run?
re information processing inequality, these bounds are pretty hard to reason about. How do we know that even the practical maximum of the quality of models we can extract from our currently available data isn't already way higher than a "superhuman" intelligence?